语音增强算法评估指南
如今语音增强算法已成为智能设备、视频会议和助听器等应用的核心,它能从嘈杂环境中“拯救”清晰的语音信号,但如何判断一个算法的好坏?这就是评估的意义所在。今天,我们来聊聊语音增强算法的评估体系,通过一个国际挑战赛作为切入点,带你一步步了解关键指标和计算方法。无论你是初学者还是从业者,这篇文章都能帮你理清思路。
前言:为什么需要评估语音增强算法?
想象一下,你开发了一个语音增强模型,自认为它能完美去除背景噪音。但在实际应用中,用户反馈“声音听起来怪怪的”或“某些噪音下完全失效”。这就是为什么评估至关重要:它提供了一个客观、量化的标准,帮助开发者识别算法的优缺点、优化性能,并与其他方法进行公平比较。
评估的作用主要体现在三个方面:
- 指导开发:通过指标反馈,迭代模型设计,避免主观偏见。
- 基准比较:在竞赛或论文中,用统一标准衡量不同算法的进步。
- 实际部署:确保算法在真实场景(如移动端或低信噪比环境)下的鲁棒性和通用性。
没有评估,算法开发就像盲人摸象;有了评估,它就成了科学工程。接下来,我们以NeurIPS 2024竞赛轨道下的URGENT 2024挑战为例,深入探讨评估体系。这个挑战聚焦于构建通用语音增强模型,强调在不同噪声、采样率和麦克风配置下的表现。
URGENT 2024挑战:评估体系的典范
URGENT 2024(Universality, Robustness, and Generalizability for EnhancemeNT)挑战旨在解决传统语音增强研究的痛点:许多算法只针对特定条件优化,缺乏跨场景泛化能力。挑战要求参赛者使用统一的公共数据集训练单一模型,处理各种失真(如噪声、混响),并支持不同输入格式(如单/多通道、不同采样率)。
这个挑战的亮点在于其全面评估框架,包括非侵入式(无参考信号)和侵入式(需参考信号)指标,以及下游任务相关指标(如词错误率WER)。它还引入主观MOS(Mean Opinion Score)评分作为最终盲测环节的补充。挑战提供ESPnet工具包的基线模型,鼓励数据增强,但严格限制训练数据来源,确保公平性。
通过这个挑战,我们可以看到评估不仅是“打分”,而是推动行业向真实场景迈进的基准。接下来,重点介绍挑战中使用的核心客观指标:PESQ、ESTOI、SDR、MCD、LSD、DNSMOS和NISQA。
评估指标详解:每个指标都在测什么?
语音增强评估指标大致分为侵入式(需要干净参考信号)和非侵入式(无需参考,模拟真实场景)。URGENT 2024挑战选用这些指标来全面考察算法的语音质量、可懂度和保真度。下面逐一解释:
PESQ (Perceptual Evaluation of Speech Quality):这是一个侵入式指标,通过比较增强后的语音与参考干净信号,评估感知质量。它关注失真和噪声对人类听觉的影响,得分范围通常为-0.5到4.5(越高越好)。在语音增强中,PESQ常用于客观测试算法的整体质量,尤其适合电话或VoIP场景。
ESTOI (Extended Short-Time Objective Intelligibility):侵入式指标,专注于评估增强语音的可懂度。它分析短时段信号,预测听者在噪声下的理解能力,得分从0到1(越高表示更易懂)。这个指标特别适用于低信噪比环境,帮助算法优化对人类认知的友好度。
SDR (Signal-to-Distortion Ratio):侵入式指标,计算期望信号能量与失真(包括噪声和伪影)能量的比率,通常以dB为单位(越高越好)。它评估增强信号的整体保真度,在多通道或复杂噪声场景中非常实用。
MCD (Mel-Cepstral Distortion):侵入式指标,量化增强信号与参考信号在梅尔倒谱系数上的差异(越低越好)。它聚焦谱失真,提供对感知质量的洞察,常用于评估算法对语音频谱的保留能力。
LSD (Log-Spectral Distance):侵入式指标,测量增强和参考信号功率谱的对数差异(越低越好)。它评估谱准确性,帮助理解算法如何保留原始语音特征,适用于频域分析。
DNSMOS (Deep Noise Suppression Mean Opinion Score):非侵入式指标,无需参考信号,使用深度学习模型预测语音质量(模拟人类评分,范围1-5)。它基于人类评级训练,适用于真实场景评估,尤其当干净参考不可用时。
NISQA (Non-Intrusive Speech Quality Assessment):同样是非侵入式指标,使用机器学习预测感知质量,无需参考。它评估整体语音质量,在参考信号缺失的实际部署中大放异彩。
这些指标组合使用,能从质量、可懂度和失真等多维度评估算法。URGENT挑战强调,非侵入式指标如DNSMOS和NISQA更贴近现实,因为真实环境中往往没有干净参考。
评测数据集:从哪里获取,如何使用?
要实际计算这些指标,需要可靠的数据集。URGENT 2024挑战通过其GitHub仓库提供官方评测数据集,托管在Hugging Face上,便于下载和使用。
- 官方评测数据集:包括验证集、非盲测集和盲测集,地址:https://huggingface.co/datasets/urgent-challenge/urgent2024_official。这些数据集包含各种失真条件下的语音样本,适合测试算法的通用性。
- MOS数据集:额外提供带人类标注MOS分数的语音质量评估数据集,地址:https://huggingface.co/datasets/urgent-challenge/urgent2024_mos。用于主观指标验证。
访问方式简单:在Hugging Face平台搜索并下载,或使用Python的datasets库加载。数据集设计覆盖不同噪声、混响和麦克风配置,确保评估的全面性。
可以参考下面的代码将hugging face中的validataion数据集以wav形式保存在本地,方便后续不同算法进行处理后,对处理结果进行评估。
| |
指标计算实践:一步步上手
计算这些指标需要工具和脚本。URGENT挑战的GitHub仓库(https://github.com/urgent-challenge/urgent2024_challenge)提供了evaluation_metrics文件夹下的实用脚本,如calculate_intrusive_se_metrics.py(处理PESQ、ESTOI、SDR、MCD、LSD等侵入式指标,支持无限SDR值处理),calculate_nonintrusive_dnsmos.py和calculate_nonintrusive_nisqa.py分别计算DNSMOS和NISQA。
计算步骤示例:
参考evaluation_metrics/README.md
- 数据准备对validation数据集中的noisy数据进行处理,得到enhanced的数据,按下面的目录结构进行组织
1 2 3 4 5 6 7 8 9📁 /path/to/your/data/ ├── 📁 enhanced/ │ ├── 🔈 fileid_1.wav │ ├── 🔈 fileid_2.wav │ └── ... └── 📁 clean/ ├── 🔈 fileid_1.wav ├── 🔈 fileid_2.wav └── ... - 生成scp文件 为clean数据和enhance数据生成对应的scp文件,在scp文件中包含两列信息,一列是一个唯一的文件id,一列是文件路径,如下
1 2 3 4 5 6 7 8 9# enhanced.scp fileid_1 /path/to/your/data/enhanced/fileid_1.flac fileid_2 /path/to/your/data/enhanced/fileid_2.flac ... # reference.scp fileid_1 /path/to/your/data/clean/fileid_1.flac fileid_2 /path/to/your/data/clean/fileid_2.flac ... - 运行脚本:例如,对于侵入式指标,运行
calculate_intrusive_se_metrics.py输入增强文件和参考文件,输出PESQ等分数。非侵入式如DNSMOS可直接输入增强语音。 - 示例代码片段:对于批量计算,仓库脚本支持文件夹输入。
1 2 3 4 5 6 7 8 9 10 11 12 13#!/bin/bash nj=8 # Number of parallel CPU jobs for speedup python=python3 output_prefix=metrics_score # PESQ, ESTOI, SDR, MCD, LSD ${python} calculate_intrusive_se_metrics.py \ --ref_scp reference.scp \ --inf_scp enhanced_webrtc.scp \ --output_dir "${output_prefix}"/scoring_webrtc \ --nj ${nj} \ --chunksize 60
在实践中,建议结合主观听测(如MOS)验证客观指标,避免“高分低体验”的情况。
结语:评估驱动创新
语音增强算法评估不是终点,而是起点。通过URGENT 2024这样的挑战,我们看到评估体系在推动算法向通用、鲁棒方向演进。未来,随着更多非侵入式指标和多模态数据的融入,评估将更贴近真实世界。
最后我们来看下之前介绍的WebRTC NS是什么水平吧,最终的指标如下所示。

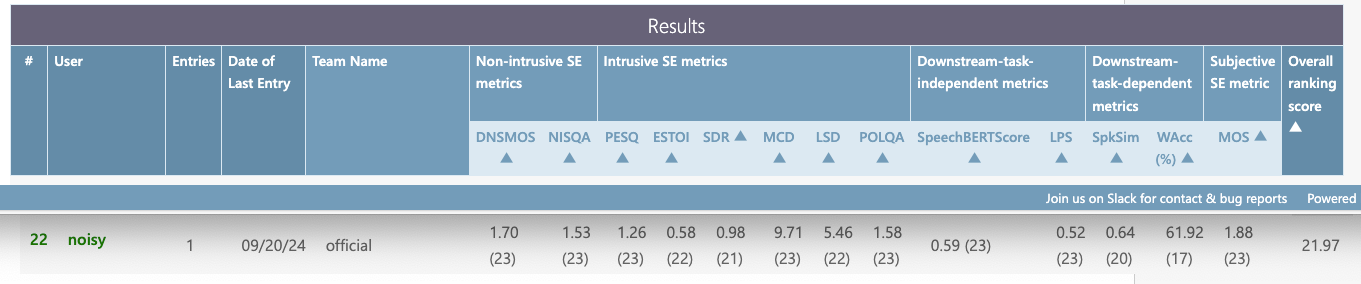
可以看到WebRTC NS的评估指标分数只比noisy的分数好一点点,可见还有很大的上升空间。传统算法或多或少都会基于一些假设,而这些假设不只小范围内是生效的,这造成了传统算法的局限性。近年深度学习基于数据驱动的方法,进一步突破这些局限性,极大提高了音频算法的效果上线。下期预告,让我们迈上深度学习时代吧。
