程序员的基本修养之代码编译
| 代码编译过程介绍,避坑指南,一些常用代码查看工具使用介绍
预处理
1.预处理的作用
宏替换:
替换 #define 定义的宏。
| |
头文件包含
替换 #include 指令为头文件的内容。
| |
条件编译
根据条件选择性地编译代码。
| |
宏展开
处理函数式宏。
| |
注释删除
移除源代码中的注释内容。
2.查看预处理结果
通过 编译器选项 可以仅执行预处理步骤。例如gcc/clang:
| |
- -E 选项表示仅执行预处理。
- 输出文件 main.i 包含预处理后的源代码。
 cmake可以通过添加配置保存中间产物
cmake可以通过添加配置保存中间产物
| |
注:一些复杂的宏操作可以通过这种方式确定最终展开后的形式
3.预处理注意事项
宏展开陷阱
注意宏的嵌套展开可能引发意外行为,用括号保护表达式。
| |
头文件滥用
导出了所有头文件并加入了搜索路径,当存在多个同名头文件时,可能会引起一些诡异的编译问题,或者运行时崩溃
- 头文件的搜索顺序 1.搜索当前目录(一般是#include “header.h”,双引号方式引用头文件) 2.通过-I指定的目录,多个目录按加入的顺序搜索 3.标准系统目录
编译
| 编译是从源文件(.c/.cpp)生成目标文件(*.o)的过程
Q1:目标文件里面包含了哪些信息?
| |
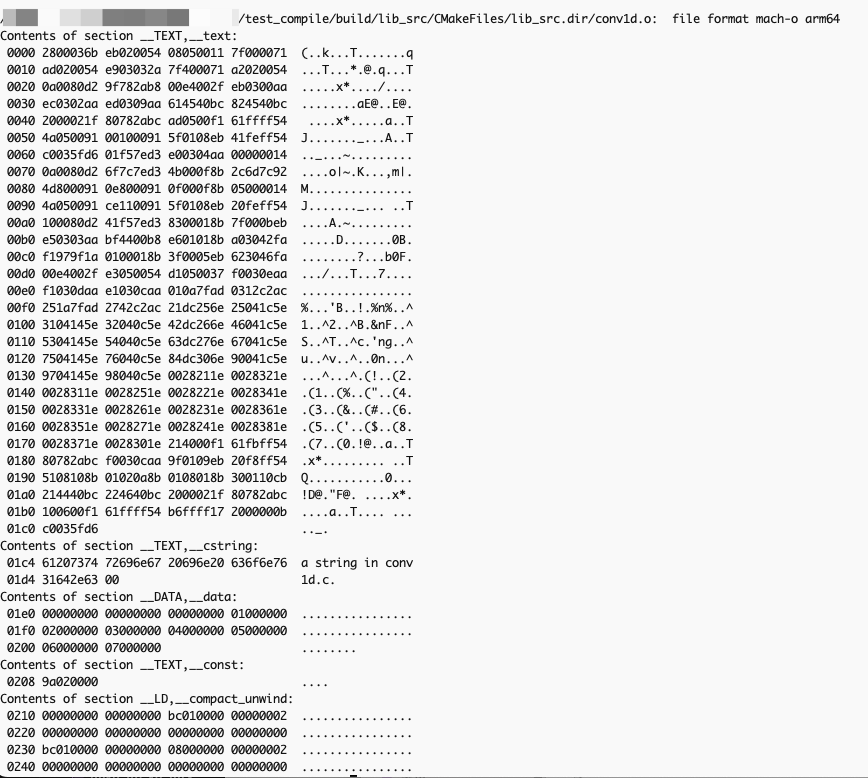
1.目标文件类型、目标架构
查看命令:
| |
| |
2.只读内容存在__TEXT段
a.__text节保存了编译后的机器码:
内容:源代码编译后的二进制机器指令,对应程序的函数和逻辑 查看命令:
| |
注:通过查看中间产物汇编文件(*.s)可以初步分析是否值得做
比如通过查看conv1d.s文件,发现已经做了循环展开,就不需要在c代码上手动做循环展开了(NEON类的SIMD在代码编译是否会进行编译优化待确定)
b.__cstring节保存了字符串
c.__const节保存了学常量
3.全局变量和静态变量保存在__DATA段
nm命令介绍 nm命令可以用来分析二进制分析的符号信息
| |
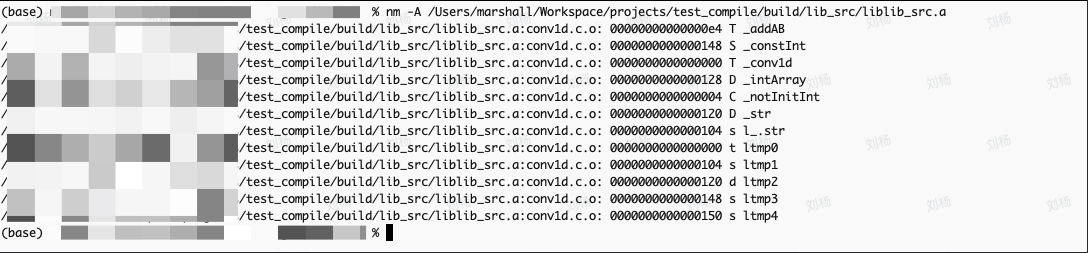
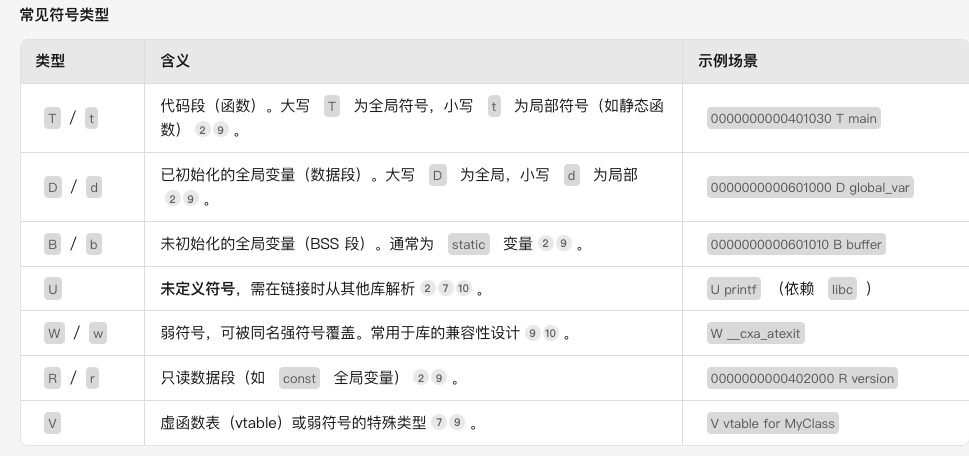 注:该命令可以用来辅助分析Undefined symbol一类的编译问题
注:该命令可以用来辅助分析Undefined symbol一类的编译问题Q2:同一份代码,保持编译参数不变的情况,两次编译最终的目标文件是否是一样的?
- 通常一致的场景 如果满足以下条件,两次编译的目标文件大概率相同:
- 代码完全不变:未修改任何源码文件(包括头文件)
- 编译参数严格一致:包括优化级别(如 -O2)、调试选项(如 -g)、路径参数(如 -I)等
- 编译器版本一致:同一版本的编译器(如 GCC 12.3)和链接器
- 环境无干扰:
a.无时间戳或随机化因素嵌入二进制文件(如代码中未使用 DATE、TIME 宏)
b.编译路径和文件系统结构相同
- 可能导致不一致的例外情况
- 时间戳或随机化因素
若源码使用 DATE、TIME 等宏,编译后生成的二进制文件会包含编译时间戳,导致两次编译结果不同。
| |
- 调试信息中的路径差异
调试信息(.debug_line 段)默认包含源码绝对路径。若两次编译的源码目录不同,目标文件会不同。
| |
链接
| 链接就是把所有目标文件合并到起,同时目标文件中在未知的地址(如在其它文件中实现的函数调用)替换成最终的地址
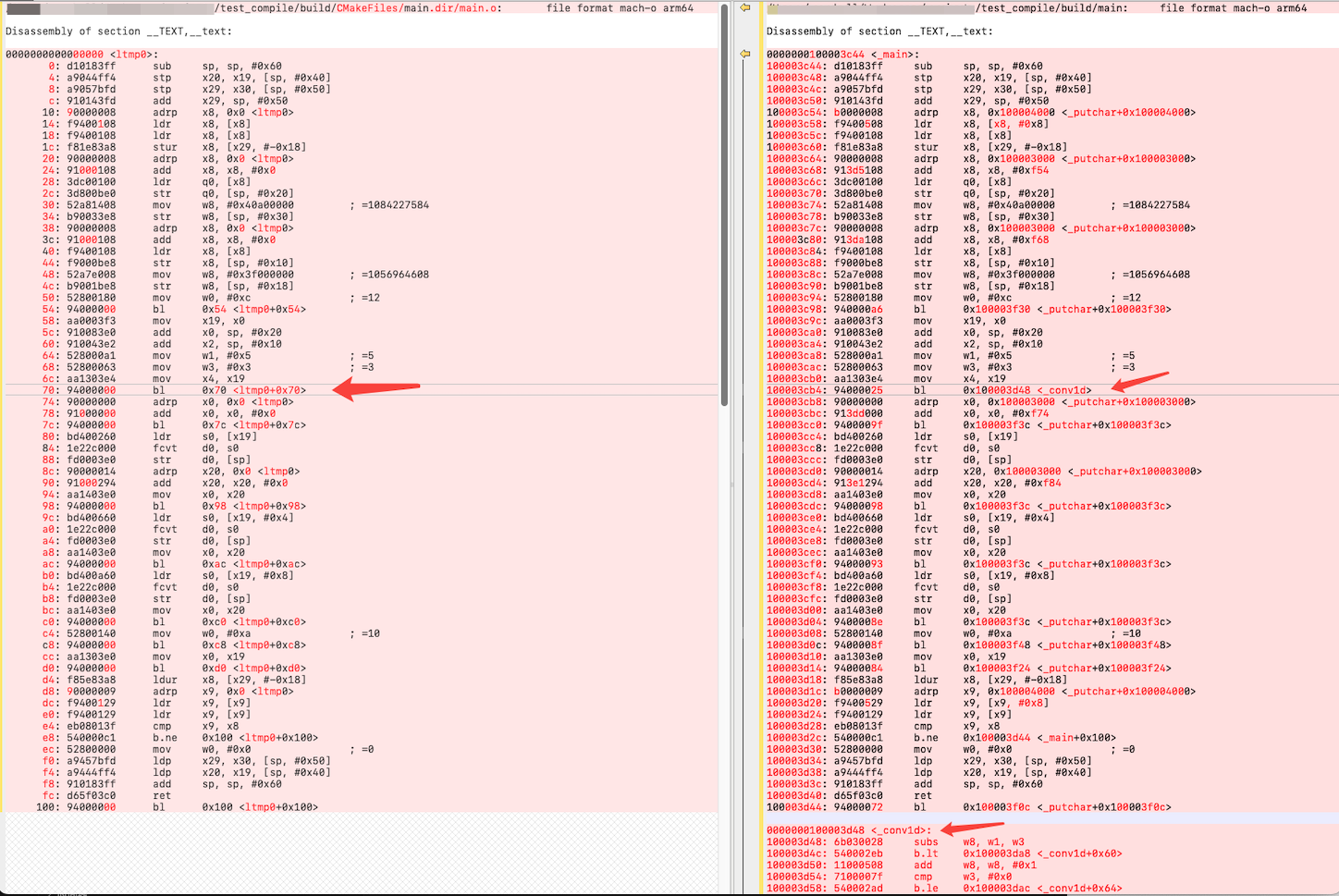 注:左侧是目标文件main.o,右侧是最终的可执行程序main
``` Shell
llvm-objdump -d 目标文件
```
注:左侧是目标文件main.o,右侧是最终的可执行程序main
``` Shell
llvm-objdump -d 目标文件
```动态库与静态库对比

macos环境下查看依赖
| |
| |
注:@rpath 会根据不同应用的配置解析到对应的目录